Para llevar a cabo el proceso de recuperación
de la información hay que tener conciencia que se siguen una serie de pasos
desde que el usuario tiene una necesidad de información, hasta que recibe la
información solicitada. Los pasos a seguir "a grosso modo" serian los
siguientes.
- El usuario tiene la necesidad de obtener información.
- Introduce en un buscador la palabra, frase o pregunta lo más concreta posible con las estrategias de búsqueda más adecuadas posibles.
- La solicitud se envía a un servidor web (hay que tener en cuenta que el usuario tendrá un equipo con un servidor conectado a Internet).
- La solicitud se envía a unos servidores de índices, en los cuales hay una serie de palabras o expresiones claves para enviarlo al lugar correspondiente.
- La solicitud se envía a las páginas guardadas por los buscadores que tienen información relevante sobre el tema especificado en la búsqueda.
- Con la información obtenida se crea una lista con las páginas seleccionadas que abarcan el tema concreto.
- Finalmente se devuelve al usuario el resultado de la búsqueda.
Imagen demostrativa:
![[google.jpg]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjCVN7JUP5G-EQ8W1UkcskgxMUaviwxCgKVvnUabKaJP_4pa1ZXRlBpL7i1pWHg0Lwy1_KdFPEXRvb_93UvOOha67jySkFib5-sh85rMtCaOeYG_INfOgY9504dIERkiKXtWcskDuUpZQ/s1600/google.jpg)
Hay que tener en cuenta que todo este proceso se
realiza recorriendo las bases de datos y servidores que pueden estar recogidos
en cualquier lugar del mundo. Visto así podríamos ver que este proceso
“debería” tardar mucho debido a la distancia a la que pueden encontrarse un
paso del siguiente, así como procesar bien la información de la búsqueda.
Pues el resultado de esta búsqueda como podemos
comprobar con un ordenador que funcione en perfectas condiciones y con una
buena conexión a Internet, tarda mili-segundos en realizarse todo el proceso.
Esto se debe en gran parte a los avances tecnológicos
con los que nos encontramos en la actualidad y los grandes avances en
recuperación de la información.
Pero nos podríamos preguntar ¿Cómo es posible recuperar la información a cerca de un tema concreto y
seleccionando la información relevante ante la que no tiene “importancia” en
tan poco tiempo?

Otra forma de explicarlo podría ser, que un usuario al escribir en el cuadro de búsqueda de un buscador lo que quiere encontrar, esas palabras se transforman en una serie de ecuaciones matemáticas que permiten reconocer las ideas clave de lo que se busca, para luego que en esas bases de datos se pueda identificar la información importante acerca del tema que el usuario busca. Una vez “atacadas” las bases de datos y reconocida la información útil se vuelve a traducir la información a modo de una lista de distintas páginas web (distintas opciones) sobre el tema especifico, en el mismo lenguaje que el usuario había buscado.
Para introducirnos de manera más profunda en el
proceso de recuperación iremos paso a paso:

En primer lugar, para que se produzca este proceso
de recuperación de la información es necesario que un usuario tenga la necesidad de buscar información.
Para satisfacer esa necesidad, si decide consultar
información en Internet, se parte de que el usuario realizará una consulta en un buscador.
Esta consulta, normalmente se hace con un lenguaje
natural, adaptado para acercarse lo máximo posible con las palabras que emplee
a unos términos que le permitan recuperar la información de forma concreta.
Para ello, se tiene en cuenta el grado de cualificación del usuario para
concretar los términos con una precisión importante, adaptar el lenguaje,
utilización de la búsqueda avanzada que permiten los buscadores, seleccionar un
tipo de buscador u otro, contrastar información recuperada y adaptar la búsqueda
en caso de que no obtenga lo que desea, etc.
Una vez formulada la consulta teniendo en cuenta la
precisión y calidad de la búsqueda según el usuario, el sistema deberá crear un
sistema de procesamiento de la búsqueda
que consiste en una serie de estrategias que sigue para concretar más la búsqueda
como por ejemplo seleccionar las palabras de una frase que tienen más
relevancia, eliminar las palabras “vacías”, adaptar la morfología de las
palabras, etc.
A continuación una vez procesada la consulta se
inicia el proceso de “ataque” a las bases de datos mediante una serie de técnicas
o estrategias matemáticas , también conocidos como modelos de recuperación de
la información, para que la recuperación sea lo más eficiente y rápida posible.
Antes de introducirnos en la explicación de los
modelos, debemos tener en cuenta varios aspectos a cerca de las bases de datos.
En estas bases de datos es necesario que la información o documentos ya hayan
sido indexadados previamente, organizados y estructurados por unos gestores
de bases de datos como pueden ser los conocidos Oracle o My SQL para que
así los “ataques” sean más eficientes.
En muchas ocasiones los servidores presentan unos
índices de estos documentos, en los cuales se encuentran una serie de términos,
palabras clave o tesauros que facilitan dicha búsqueda.
Tener los resultados ordenados, es un factor clave
para que la recuperación se haga de forma eficiente y en el menor tiempo
posible. Pero hay otras estrategias o características de los documentos que también
es importante que se tengan en cuenta para que la información se recupere de
manera más efectiva, como es que los algoritmos de búsqueda tengan en cuenta los
siguientes criterios de selección:
- Tienen en cuenta los enlaces (hipervínculos).
- Estructura HTML.
- Tipo de lenguaje (JavaScript, etc.).
- Calidad de la información.
- Idioma.
- Cantidad de documentos indexados.
- Actualización periódica de la web.
- Duplicados de web (solo se elegiría una)
- Depende de si el texto en un documento va seguido o fragmentado (se puede fragmentar por usar lenguaje JavaScript.
- Popularidad de la página.
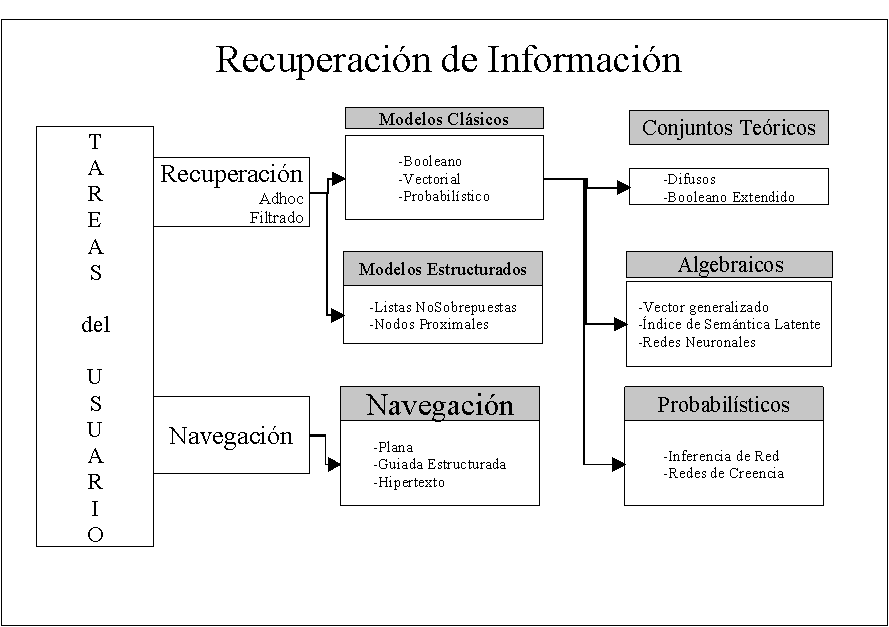
A continuación vamos hablar de algunos de los
modelos de recuperación de la información. Estos modelos por lo general se
basan en procesos de “ataque” a las bases de datos para obtener información relevante
sobre un tema concreto que en el que un usuario ha definido mediante la
consulta. Estos modelos normalmente se rigen por unos algoritmos matemáticos
que les “guían” a seleccionar los documentos más relevantes.
Los modelos
de recuperación suelen basarse en una serie de características o términos
comunes para diferenciar elementos en la búsqueda como son:
- (D): “Es el conjunto de representaciones lógicas de los documentos guardados”
- (Q) = (Queries): “Conjunto de vistas lógicas de las necesidades del usuario”
- (F): En este apartado se crean unos modelos sobre documentos, queries y su relación
- Modelo vectorial: Espacios vectoriales y álgebra”
- Modelo Probabilístico: Teorías de probabilidad, modelos bayesianos, etc.
- (R (Qi, Dj)): Es la función de la clasificación. Crea el orden en los documentos en función de los queires.
Debemos tener en cuenta que los documentos, en
función de lo que se busca, pueden contener unos términos que son los que se
establecen como relevantes, del tema seleccionado. Sin embargo puede que haga
dos documentos donde podemos encontrar esos términos, pero la relevancia puede
ser distinta en uno u otro, debido a que los términos pueden tener más peso en
uno que en otro. De modo que a más peso, más relevancia.
Los modelos distintos modelos son los encargados de seleccionar
los términos, otorgarles peso y establecer una relación entre ellos, con lo
cual de esto modo priorizan un documento ante otro.
Terminología:
- (Ki)= Indice/Termino
- (Dj)= Documento
- (Wij): Peso de Ki-Dj
Método Booleano (1)
Este modelo es muy antiguo o clásico pero aun así es
uno de los más utilizados en la actualidad. Está basado en la teoría de
conjuntos y álgebra de boole.
Este modelo explicado de forma general consiste en
que la búsqueda o “ataque” a los documentos lo hace con el fin de encontrar
una serie de términos específicos para encontrar una relevancia con lo que se pide en la consulta.
Para llevar a cabo esto, utiliza una serie de
estrategias representadas como fórmulas matemáticas que por ejemplo se de
manera muy básica pueden representarse así: Se presenta un término como Ti, si
este término se encuentra en el documento se representa como Di y si no se
encuentra se representa como NONti.
Los términos utilizados que el usuario presenta en
la consulta de manera lógica pueden ser “traducidos” del siguiente modo: (Y, O
NO) traducidos como (AND, OR, NOT)
Este modelo presenta unas ventajas como:
- Fácil de emplearlo y entender el funcionamiento
- Utiliza conceptos que son intuitivos
- Utiliza formalismos.
Pero también presenta desventajas como:
- Puede recuperar mucho o muy pocos documentos
- Difícil clasificarlos como mas importante o menos.
- Es difícil traducir todo el mensaje booleano
- A todos los términos se les otorga el mismo peso
- Modelo que recupera datos más bien que información.
- Puede ser confuso ya que al realizar una búsqueda puedes escribir perros y gatos, (perros AND gatos), cuando en realidad debería ser (perros OR gatos).
(1) Información obtenida de:
http://es.wikipedia.org/wiki/Modelo_booleano
http://www.slideshare.net/caritosuarez/recuperacin-de-informacin-de-la-teora-a-la-prctica
http://slideplayer.es/slide/1856908/
http://es.wikipedia.org/wiki/Modelo_booleano
http://www.slideshare.net/caritosuarez/recuperacin-de-informacin-de-la-teora-a-la-prctica
http://slideplayer.es/slide/1856908/
Modelo Vectorial (2)
Este modelo considera que a cada término se le
aplica un valor vectorial. Esto se puede
explicar cómo que da más o menos relevancia a un documento en función de cada
término.
*Un vector representa a un documento o query.
Un documento tendrá mayor o menor relevancia en
función de los ángulos de los vectores en cada documento, comparando documentos.
Los ángulos se crearán según el vector (término) que
se busque.
Si hay mucha frecuencia de vectores un documento tendrá
mas peso. Pero si hay muchos documentos con esos vectores el peso tenderá a
disminuir.
Para realizar el proceso se crean una serie de
algoritmos muy complejos, difícil de entender para un usuario común.

Este modelo presenta una serie de ventajas:
- Presenta un ranking de documentos con en función de relación de términos y peso.
- Es más específico que otros modelos.
Desventajas:
- Los documentos con un gran volumen quedan poco representados debido a que presentan pocos valores en común.
- Puede considerar partes de palabras como términos aceptados, cuando en realidad no lo son.
- Si se utiliza un lenguaje distinto como un sinónimo ante el término que se busca, da como negativo.
http://es.wikipedia.org/wiki/Modelo_de_espacio_vectorial
http://slideplayer.es/slide/1856908/
Modelo
Probabilístico (3)
Este modelo establece unos términos relevantes en función
de la consulta, como los otros vistos, y en función de si aparece o no se le
otorga más relevancia al documento.
En función de la probabilidad en que un documento
pueda ser más relevante que otro los categoriza y los presenta como resultado
al usuario.
Una vez ofrecido al usuario, según si le ha servido
el documento (ha sido relevante o no) va guardando los más relevantes para así
en la siguiente búsqueda ofrecerlos en un lugar más adecuado del ranking de
respuestas.
Este modelo puede presentar resultados correctos o
útiles si se tienen almacenados grandes cantidades de respuestas de usuarios
como relevantes o no, sin embargo si eres de los primeros que han obtenido las
respuestas puede no ser información valida, e incluso lo que para una persona
puede ser válido para otra no lo es.
Estos son algunos de los modelos más utilizados para
la recuperación de la información. Una vez recuperados, los resultados han de
presentarse al usuario de forma ordenada de manera decreciente en función del
grado de relevancia que el sistema haya determinado.
Para representarlos en un ranking se tienen en
cuenta una serie de aspectos como si a usuarios anteriores les han sido
relevantes, exhaustividad, numero de clics, nivel de enlazamientos, etc.
Y una vez que le es ofrecida al usuario la
información, si esta no es lo suficiente relevante, el usuario deberá volver
hacer una consulta puntualizando, concretando aspectos e intentando acercarse
lo máximo posible a lo que realmente busca.
Hemos podido comprobar “muy por encima” el proceso
que se tiene que desarrollar para recuperar la información. Podemos ver la gran
complejidad y trabajo que tiene este ámbito de la informática, y cuanto más
investiguemos sobre este tema más complejo aun se hace con lo cual es
importante concienciarse del número de horas, días y años, investigadores,
trabajadores, recursos y demás, que se han tenido que invertir para que un
usuario común sin ningún tipo de conocimientos, pueda obtener información de
cualquier parte del mundo, estructurada y adaptada en el mayor grado posible a
que sea relevante con lo que estamos buscando, y todo esto en un solo clic en
el ratón obtenemos los resultados en cuestión de milisegundos.
(3) Información obtenida de: http://es.wikipedia.org/wiki/Modelo_probabil%C3%ADstico
Imagen demostrativa del proceso completo:
(3) Información obtenida de: http://es.wikipedia.org/wiki/Modelo_probabil%C3%ADstico
Imagen demostrativa del proceso completo:

Como opinión personal, considerándome un usuario con
unos conocimientos básicos de informática, a medida que voy investigando tanto
en este como en los demás temas, me voy dando cuenta de la ignorancia que tengo
y que hay en general sobre estos temas y me voy concienciando de los grandes
progresos y avances que se han ido desarrollando, todo el trabajo que hay
invertido, además de recursos y demás trabajo “oculto” para los que no nos
dedicamos a esto, y pienso que es importante que las personas que hablan de la informática
como que es algo sencillo que cualquiera puede conocer bien a base de tutoriales, (como
he escuchado), que dejen la ignorancia a un lado y si de verdad quieren saber lo
que hay detrás de lo que tenemos actualmente, que se informen.
Relacionado con este tema pienso que aún queda por
mejorar, ya que hasta que no se descubra el modo en el que se pueda recuperar
la información totalmente relevante de forma precisa, eficiente y rápida, aun
se debe seguir investigando.
Planteo algunas cuestiones abiertas para finalizar
sobre este tema:
- ¿Realmente crees que es posible que algún día se pueda recuperar la información concreta que un usuario busca?
- Sería acertado proponer que por ejemplo: un buscador ofreciera unas respuestas ante una consulta, ante esas respuestas el mismo buscador te fuera haciendo preguntas específicas y el usuario contestando, hasta llegar a los documentos más relevantes, ¿Qué opinas?
- ¿Desarrollar un sistema en el que puedas realizar la consulta en otro método de comunicación que no sea el escrito y que el sistema pudiera detectar realmente las necesidades del usuario podría ser una opción?
- ¿Qué mas ideas propondrías?


Documentación utilizada para desarrollar todo el tema
- http://slideplayer.es/slide/1856908/
- http://ict.udlap.mx/people/carlos/is346/admon08.html
- http://www.mariapinto.es/e-coms/recu_infor.htm
- http://ccdoc-tecnicasrecuperacioninformacion.blogspot.com.es/search/label/03.-%20Conceptos%20de%20Recuperaci%C3%B3n%20de%20Informaci%C3%B3n
- http://www.slideshare.net/caritosuarez/recuperacin-de-informacin-de-la-teora-a-la-prctica
- http://es.wikipedia.org/wiki/Modelo_probabil%C3%ADstico
- http://es.wikipedia.org/wiki/Modelo_de_espacio_vectorial
- http://es.wikipedia.org/wiki/Modelo_booleano
No hay comentarios:
Publicar un comentario